Introduction of Machine Learning
机器学习可以揭示数据背后的真实含义。
监督学习需要用户知道目标值,简单的说就是知道数据在找什么。而无监督学习则无需用户知道搜寻的目标,只需要从算法程序中得到这些数据的共同特征。
保证算法应用的正确性:
- 确保算法应用可以正确处理简单的数据。
- 将现实世界中得到的数据格式化为算法可以处理的格式。
- 将步骤2得到的数据输入到步骤1的算法中,检验算法的运行结果。
千万不要忽略前两个步骤而直接跳到步骤3来检验算法处理真实数据的效果。任何复杂系统都是由基础工程构成的,尤其是算法出现问题时,增量地搭建系统可以确保我们及时找到问题出现的位置和原因。
后续根据监督学习和无监督学习进行分类讨论。
在监督学习中,我们只需要给定输入样本,机器就可以从中推演出指定目标变量的可能结果。监督学习相对比较简单,机器只需从输入数据中预测合适的模型,并从中计算出目标变量的结果。
监督学习一般使用两种类型的目标变量:标称型和数值型。标称型目标变量的结果只在有限目标集中取值,如真与假,动物分类集合;数值型目标变量则可以从无限的数值集合中取值,一般用于回归分析。
Key Terminology
我们使用机器学习的某个算法进行分类结果,首先要做的是算法训练,即学习如何分类。通常我们为算法输入大量的已分类数据作为算法的训练集。训练集是用于训练机器学习算法的数据样本集合。目标变量是机器学习算法的预测结果。
在分类算法中目标变量的类型通常是标称型的,而在回归算法中通常是连续型的。
训练样本集必须确定知道目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。
当机器学习程序开始运行时,使用训练样本集作为算法的输入,训练完成后输入测试样本,由程序决定样本属于哪个类别。
Primary Mission
监督学习中的任务:
1.将实例数据划分到合适的分类中。
2.回归,主要用于预测数值型数据。
无监督学习中的任务:
数据没有类别信息,也不会给定目标值。
1.在无监督学习中,将数据集合分成由类似的对象组成的多个类的过程被称为聚类。
2.将寻找描述数据统计值的过程称之为密度估计。
Overview of Algorithm
| 监督学习的用途 | |
|---|---|
| K-近邻算法 | 线性回归 |
| 朴素贝叶斯算法 | 局部加权线性回归 |
| 支持向量机 | Ridge回归 |
| 决策树 | Lasso最小回归系数估计 |
| 无监督学习的用途 | |
|---|---|
| K-均值 | 最大期望算法 |
| DBSCAN | Parzen窗设计 |
How to choose
首先考虑使用机器学习算法的目的。如果想要预测目标变量的值,则可以选择监督学习算法,否则选择无监督学习算法。
如果确定选择监督学习算法后,需要进一步确定目标变量类型。
- 如果目标变量是离散型,如是/否,1/2/3,红/黄/黑等,则可以选择分类算法。
- 如果目标变量是连续型的数值,则需要选择回归算法。
如果不想预测目标变量的值,则可以选择无监督学习算法。
- 需要将数据划分为离散的组。如果这是唯一的需求,则使用聚类算法。
- 需要估计数据与每个分组的相似程度,需要使用密度估计算法。
Steps in Machine Learning
- 收集数据
- 准备输入数据
- 分析输入数据。确保数据集中没有垃圾数据。
- 训练算法(监督学习)
- 测试算法。
- 使用算法。将机器学习算法转化为应用程序,执行实际任务。
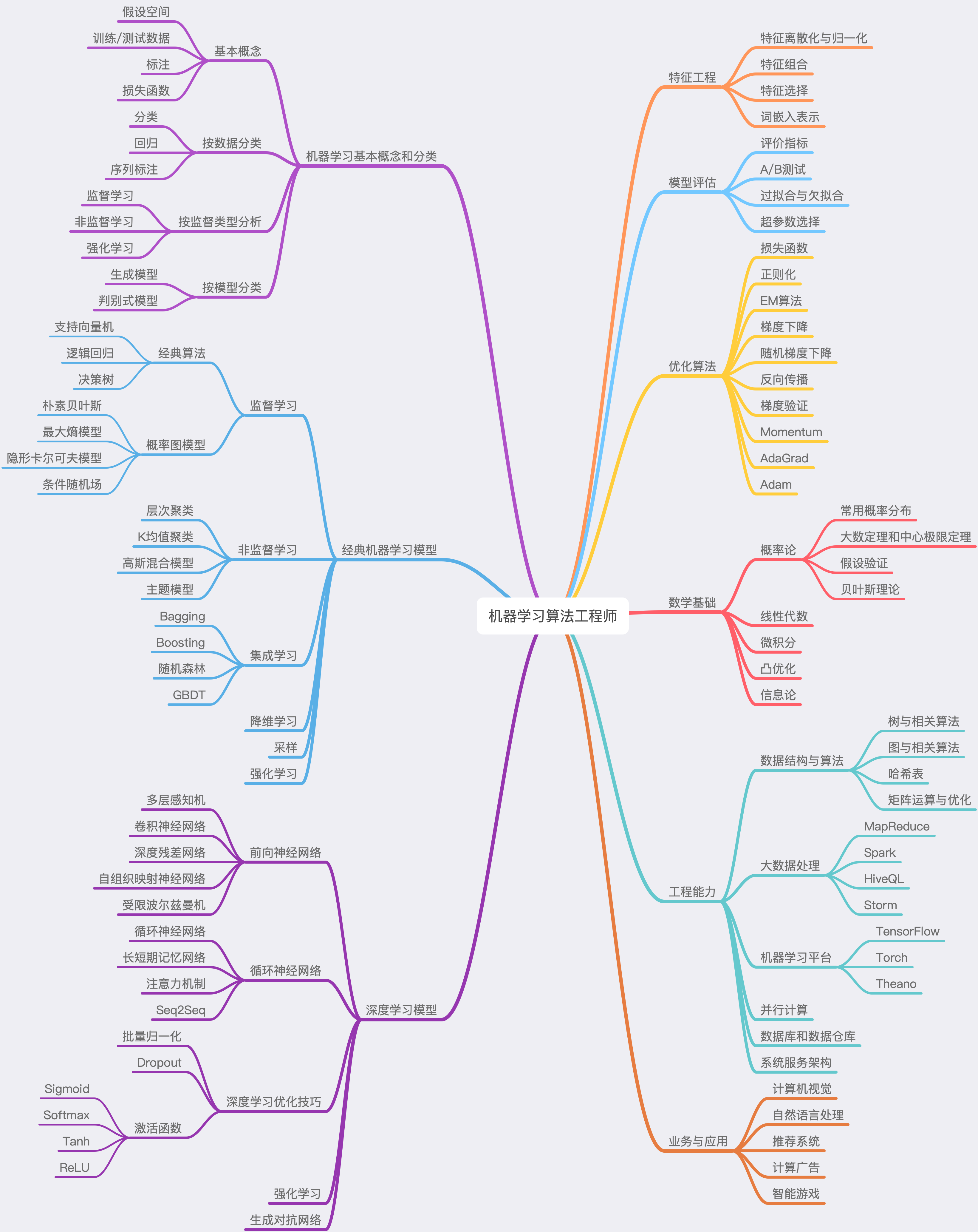
优化算法
损失函数(目标函数)
分类问题
- 平方差损失函数
- 交叉熵损失
多用于多分类
回归问题
- 平方差损失函数
- 绝对值损失
正则化
EM算法
梯度下降
随机梯度下降
反向传播
梯度验证
Momentum
AdaGrad
Adam
模型评估
评价指标
A/B测试
过拟合于欠拟合
超参数选择
DeepLearning Model
CNN
移步☞博文:CNN
RNN
GAN
AutoML
深度学习优化技巧
批量归一化BN
Dropout
激活函数
Sigmoid
二分类逻辑回归模型

Softmax
多分类逻辑回归模型
, k=1,2,…..,K-1
, k=K